| ACCUEIL | Les autres types de variables | DECOUVERTE | APPLICATION | EVALUATION |
Les autres types de variables
| Sommaire de cette page | |
|
|

Rappel des 4 types de base : int, float, str et list
Nous connaissons déjà quelques types de variables de base :
- les nombres entiers
- les nombres décimaux
- les chaînes de caractères
- les listes
Lorsqu'une variable est créée, Python garde en interne le type exact de cette variable. Pour connaître le type d'une variable il faut utiliser la fonction type de Python. Exemples :
>>> a=3
>>> type(a)
<class 'int'>
>>> b=7.89
>>> type(b)
<class 'float'>
>>> c="bonjour"
>>> type(c)
<class 'str'>
>>> d=[1,2,3,4]
>>> type(d)
<class 'list'>
D'après les informations renvoyées par la fonction type on constate que :
- les nombres entiers sont étiquetés int
- les nombres décimaux sont étiquetés float
- les chaînes de caractères sont étiquetés str
- les listes sont étiquetés list
La fonction int() permet de convertir une valeur en nombre entier :
>>> int(5.42)
5
>>> int(19/7)
2
La fonction float() permet de convertir une valeur en nombre décimal (nombre à virgule) :
>>> float(5)
5.0
>>> float(True)
1.0
La fonction str() permet de convertir un objet en chaîne de caractères :
>>> str(87)
'87'
>>> str([1,2,3])
'[1, 2, 3]'
>>> str(19/7)
'2.7142857142857144'
La fonction list() permet de convertir un objet en liste :
>>> list(range(5))
[0, 1, 2, 3, 4]
>>> list('bonjour')
['b', 'o', 'n', 'j', 'o', 'u', 'r']
A retenir :
Pour connaître le type exact d'une variable il faut utiliser la fonction type de Python.
La fonction int(x) permet de convertir l'objet x en nombre entier
La fonction float(x) permet de convertir l'objet x en nombre décimal
La fonction str(x) permet de convertir l'objet x en chaîne de caractères
La fonction list(x) permet de convertir l'objet x en liste
Les booléens
Écriture et définition d'un booléen
Une variable Booléenne (ou variable logique) est une variable qui ne peut prendre que 2 valeurs : True ou False
Le terme "booléen" vient du nom du mathématicien britannique George BOOLE qui a inventé la logique au 19ème siècle.
L'adjectif "booléen" peut être considéré comme un synonyme de "logique" signifiant "qui est soit vrai soit faux" :
- True signifie "vrai" en fançais et correspond au 1 logique
- False signifie "faux" en fançais et correspond au 0 logique.
Une variable booléennes peut être initialisée en utilisant les mots clés True et False qui s'écrivent avec une majuscule :
>>> a=True
>>> b=False
>>> type(a)
<class 'bool'>
>>> type(b)
<class 'bool'>
On remarque que les variables logiques, ou booléennes, sont étiquetées bool si on les teste avec la fonction type.
Une variable booléennes peut également être initialisée par le résultat d'un test qui renvoie soit vrai (True) soit faux (False) :
>>> a=5>3
>>> a
True
>>> b=7<4
>>> b
False
>>> c=12!=14
>>> c
True
La fonction bool() permet de convertir une valeur en booléen qui vaudra soit True soit False :
>>> bool(1)
True
>>> bool(0)
False
>>> bool(2)
True
>>> bool(78.3)
True
>>> bool(-5)
True
>>> bool(-423.97)
True
>>> bool('oui')
True
>>> bool('faux')
True
>>> bool(0.0)
False
On remarque qu'une valaur non nulle est toujours convertie en True. Seule une valeur nulle est convertie en False par la fonction bool().
>>> bool('oui')
True
>>> bool('')
False
>>> bool([1,2,3])
True
>>> bool([])
False
Enfin on remarque qu'une chaîne de caractères vide est convertie en False, alors qu'une chaîne non vide est convertie en True.
De même la liste vide est convertie en False, alors qu'une liste non vide est convertie en True.
Les fonctions all() et any()
La fonction all() attend en paramètre une liste de booléens. Elle renvoie True seulement si tous les booléens valent True. Elle renvoie False à partir du moment ou au moins un booléen vaut False. Exemples :
>>> all([True,True])
True
>>> all([True,False])
False
>>> all([True,False,True,True])
False
>>> all([True,True,True,True])
True
>>> all([0,1,0,1,0,1])
False
>>> all([1,1,1])
True
La fonction all() est comparable à un ET logique : elle renvoie True seulement si tous les éléments valent True, et False dans tous les cas contraires.
La fonction any() attend en paramètre une liste de booléens. Elle renvoie False seulement si tous les booléens valent False. Elle renvoie True à partir du moment ou au moins un booléen vaut True. Exemples :
>>> any([True,False])
True
>>> any([False,False])
False
>>> any([False,False,True])
True
>>> any([0,0])
False
>>> any([0,1])
True
>>> any([1,0])
True
>>> any([1,1])
True
La fonction any() est comparable à un OU logique : elle renvoie False seulement si tous les éléments valent False, et True dans tous les cas contraires.
A retenir :
Les booléens :
Une variable booléenne (ou variable logique) ne peut prendre que 2 valeurs : True (vrai) ou False (faux)
Tous les tests logiques de comparaisons renvoient un booléen (exemple : a>5)
La fonction bool(x) permet de convertir l'objet x en booléen
La fonction all(x) attend une liste de booléens en paramètre et réalise un ET logique
La fonction any(x) attend une liste de booléens en paramètre et réalise un OU logique
Les ensembles
Écriture et définition d'un ensemble
Un ensemble est un type composé contenant une collection d'objets.
Un ensemble se définit entre accolades. Exemple :
>>> e={1,2,3,4}
Si on teste le type de la variable e Python nous donne le type set :
>>> type(e)
<class 'set'>
La fonction print peut afficher la totalité d'un ensemble :
>>> print(e)
{1, 2, 3, 4}
Très important : contrairement à une liste un ensemble ne peut pas contenir plusieurs fois le même élément :
>>> e={2,5,6,3,5,4,1,5,4,2,3,6,2,1,4,5,5,4,2}
>>> print(e)
{1, 2, 3, 4, 5, 6}
Un ensemble est un type itérable, c'est-à-dire que placé dans une boucle for, il fournira un par un chacun de ses éléments :
>>> for i in {1,2,3,4}:
... print(i)
...
1
2
3
4
>>>
Attention : contrairement à une liste, dans un ensemble les éléments ne sont pas ordonnés. Cela veut dire que par exemple les ensemble {1,2,3,4} et {4,2,3,1} sont strictement identiques pour Python :
>>> {1,2,3,4}=={2,4,3,1}
True
Il en résulte que lors de l'extraction des éléments d'un ensemble par une boucle for l'ordre dans lequel les éléments sont renvoyés n'est pas garanti :
>>> e={'a',1,'b',2,'c',3}
>>> for i in e:
... print(i)
...
a
1
c
3
2
b
Enfin, comme le montre l'exemple précédent, un ensemble peut contenir des objets de différents types (nombres entiers, nombres décimaux ou chaîne de caractères) :
>>> e={3.14,"bonjour",4000,"Python",6789.5432,0}
>>> print(e)
{0, 4000, 6789.5432, 3.14, 'Python', 'bonjour'}
On constate encore une fois dans l'exemple précédent que l'ordre des éléménts enregistrés dans l'ensemble n'est pas garanti : la notion d'ordre n'existe pas pour les ensembles.
Les opérations applicables aux ensembles
L'opérateur in permet de tester l'appartenance d'un élément à un ensemble :
>>> e={1,2,3,4}
>>> 2 in e
True
>>> 7 in e
False
La fonction len permet de connaître le nombre d'éléments enregistrés dans un ensemble :
>>> e={1,2,3,4}
>>> len(e)
4
>>> f={3.14,"bonjour",4000,"Python",6789.5432,0}
>>> len(f)
6
La fonction set permet de convertir une liste (ou tout autre objet composé) en un ensemble :
>>> liste=[1,2,3,4]
>>> e=set(liste)
>>> print(liste)
[1, 2, 3, 4]
>>> type(liste)
<class 'list'>
>>> print(e)
{1, 2, 3, 4}
>>> type(e)
<class 'set'>
La méthode add permet d'ajouter un élément à un ensemble :
>>> e={1,2,3,4}
>>> e.add(5)
>>> print(e)
{1, 2, 3, 4, 5}
La méthode remove permet de supprimer un élément dans un ensemble :
>>> e={1,2,3,4}
>>> e.remove(3)
>>> print(e)
{1, 2, 4}
Python possède plusieurs opérateurs permettant d'effectuer les opérations mathèmatiques classiques sur les ensembles, tellles que l'union ou l'intersection.
Imaginons un ensemble e1 contenant les éléments 1, 2, 3 et 4, et un ensemble e2 contenant les éléments 3, 4, 5 et 6. Voici la représentation graphique de ces deux ensembles :
Représentation graphique de deux ensembles |
|---|
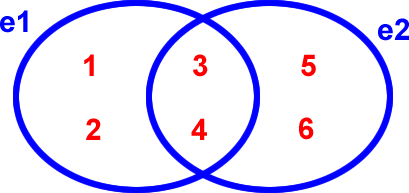
Les éléments 3 et 4 appartiennent à la fois à e1 et à e2 mais ne sont représentés qu'une seule fois.
L'intersection :
L'opérateur & calcule l'intersection de 2 ensembles : e1&e2 renvoie un nouvel ensemble contenant les éléments appartenant aux 2 ensembles à la fois (sans doublons) :
>>> e1={1,2,3,4}
>>> e2={3,4,5,6}
>>> e1&e2
{3, 4}
L'intersection renvoie un ensemble contenant les éléments appartenant à la fois à e1 et à e2 :
e1 & e2
Intersection de deux ensembles : ET |
|---|
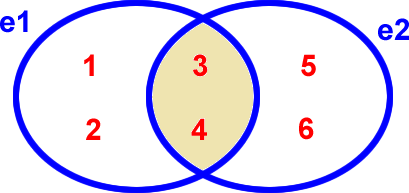
Remarque : l'intersection de deux ensembles est similaire au ET logique (e1 ET e2)
L'union :
L'opérateur | calcule l'union de 2 ensembles : e1|e2 renvoie un nouvel ensemble contenant les éléments appartenant à au moins un ensemble (sans doublons) :
>>> e1={1,2,3,4}
>>> e2={3,4,5,6}
>>> e1|e2
{1, 2, 3, 4, 5, 6}
L'union de deux ensembles renvoie un ensemble comprenant les éléments appartenant au premier, au deuxième, ou aux deux ensembles.
L'union renverra alors un ensemble contenant tous les éléments de e1 et de e2 réunis :
e1 | e2
Union de deux ensembles : OU |
|---|
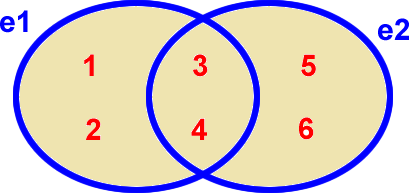
Remarque : l'union de deux ensembles est similaire au OU logique (e1 OU e2 ou les 2)
La différence symétrique :
L'opérateur ^ calcule la différence symétrique de 2 ensembles : e1^e2 renvoie un nouvel ensemble contenant les éléments appartenant soit à e1, soit à e2, mais n'appartenant pas à la fois à e1 et à e2 :
>>> e1={1,2,3,4}
>>> e2={3,4,5,6}
>>> e1^e2
{1, 2, 5, 6}
La différence symétrique sélectionne les éléments appartenant exclusivement à un seul ensemble (pas aux 2) :
e1 ^ e2
Différence symétrique de deux ensembles : OU-Exclusif |
|---|
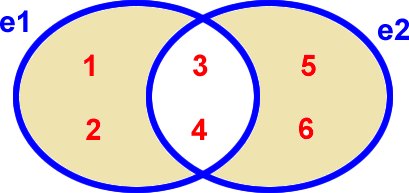
Remarque : la différence symétrique de deux ensembles est similaire au OU-Exclusif logique (e1 et pas e2 OU e2 et pas e1 : exclusivement un seul)
On peut également constater que la différence symétrique correspond à l'union à qui on a enlevé l'intersection :
différence symétrique = union - intersection
e1^e2 = (e1|e2)-(e1&e2)
En voici une illustration :
>>> e1={1,2,3}
>>> e2={3,4,5}
>>> e1^e2
{1, 2, 4, 5}
>>> (e1|e2)-(e1&e2)
{1, 2, 4, 5}
>>> e1={1,2,3,4,5}
>>> e2={3,4,5,6,7}
>>> e1^e2
{1, 2, 6, 7}
>>> (e1|e2)-(e1&e2)
{1, 2, 6, 7}
>>> e1={1,2,3}
>>> e2={4,5,6}
>>> e1^e2
{1, 2, 3, 4, 5, 6}
>>> (e1|e2)-(e1&e2)
{1, 2, 3, 4, 5, 6}
>>> e1={1,2,3}
>>> e2={1,2,3}
>>> e1^e2
set()
>>> (e1|e2)-(e1&e2)
set()
La différence
L'opérateur - calcule la différence de 2 ensembles : e1-e2 renvoie un nouvel ensemble contenant les éléments de e1 qui n'appartiennent pas à e2 :
>>> e1={1,2,3,4}
>>> e2={3,4,5,6}
>>> e1-e2
{1, 2}
>>> e2-e1
{5, 6}
La différence n'est pas commutative : e1-e2 ne donne pas le même résultat que e2-e1
Voici graphiquement ce que sélectionne la différence e1-e2 :
e1 - e2
Différence e1 - e2 |
|---|
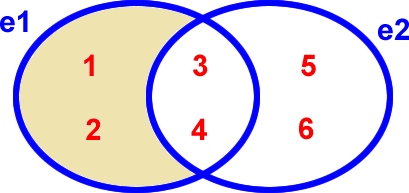
Et voici graphiquement ce que sélectionne la différence e2-e1 :
e2 - e1
Différence e2 - e1 |
|---|
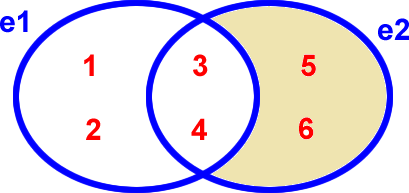
De plus la différence n'est pas associative : (e1-e2)-e3 ne donne pas le même résultat que e1-(e2-e3).
Exemple :
>>> e1={1, 2, 3}
>>> e2={3, 4, 5}
>>> e3={1, 5, 6}
>>> e1-e2-e3
{2}
>>> (e1-e2)-e3
{2}
>>> e1-(e2-e3)
{1, 2}
Sans parenthèse on effectue les opérations "différence" dans l'ordre de l'expression (de gauche à droite)
Remarque : la différence de deux ensembles est similaire à la soustraction en mathématique (e1 moins e2 n'est pas égal à e2 moins e1)
Priorité entre les opérateurs
Comme pour tous les opérateurs, il y a un ordre de priorité entre les opérateurs appliqués aux ensembles.
Testons la priorité des opérateurs deux à deux afin d'en déduire l'ordre de priorité des 4 opérateurs & | ^ et - .
Test de priorité entre l'intersection & et l'union | :
>>> e1={1,2,3,4}
>>> e2={3,4,5,6}
>>> e3={5,6,7,8}
>>> e1|e2&e3
{1, 2, 3, 4, 5, 6}
>>> (e1|e2)&e3
{5, 6}
>>> e1|(e2&e3)
{1, 2, 3, 4, 5, 6}
>>> e3&e2|e1
{1, 2, 3, 4, 5, 6}
Conclusion : & est prioritaire devant | (tout comme en logique où le ET est prioritaire devant le OU)
Test de priorité entre l'union | et la différence symétrique ^ :
>>> e1={1,2,3}
>>> e2={3,4,5}
>>> e3={5,6,1}
>>> e1|e2^e3
{1, 2, 3, 4, 6}
>>> e3^e2|e1
{1, 2, 3, 4, 6}
>>> (e3^e2)|e1
{1, 2, 3, 4, 6}
>>> e3^(e2|e1)
{2, 3, 4, 6}
>>> (e1|e2)^e3
{2, 3, 4, 6}
>>> e1|(e2^e3)
{1, 2, 3, 4, 6}
Conclusion : ^ est prioritaire devant |
Test de priorité entre l'intersection & et la différence symétrique ^ :
>>> e1={1,2,3}
>>> e2={3,4,5}
>>> e3={5,6,1}
>>> e1&e2^e3
{1, 3, 5, 6}
>>> e1&(e2^e3)
{1, 3}
>>> (e1&e2)^e3
{1, 3, 5, 6}
Conclusion : & est prioritaire devant ^
Remarque : comme & est prioritaire devant ^, et comme ^ est prioritaire devant |, on en déduit que & est forcément prioritaire devant |
Test de priorité entre l'intersection & et la différence - :
>>> e1={1,2,3,4}
>>> e2={4,5,6,7}
>>> e3={7,8,9,1}
>>> e2-e3&e1
{4}
>>> (e2-e3)&e1
{4}
>>> e2-(e3&e1)
{4, 5, 6, 7}
Conclusion : - est prioritaire devant &
On en déduit que la différence (-) est prioritaire devant tous les opérateurs logiques (& | ^).
Test de priorité entre l'union | et la différence - :
Comme - est prioritaire devant &, et comme & est prioritaire devant |, on en déduit que - est forcément prioritaire devant |
Démonstration :
>>> e1={1,2,3,4}
>>> e2={4,5,6,7}
>>> e3={7,8,9,1}
>>> e1|e2-e3
{1, 2, 3, 4, 5, 6}
>>> e1|(e2-e3)
{1, 2, 3, 4, 5, 6}
>>> (e1|e2)-e3
{2, 3, 4, 5, 6}
Conclusion : - est prioritaire devant |
Test de priorité entre la différence symétrique ^ et la différence - :
Comme - est prioritaire devant &, et comme & est prioritaire devant ^, on en déduit que - est forcément prioritaire devant ^
Démonstration :
>>> e1={1,2,3,4}
>>> e2={4,5,6,7}
>>> e3={7,8,9,1}
>>> e1^e2-e3
{1, 2, 3, 5, 6}
>>> (e1^e2)-e3
{2, 3, 5, 6}
>>> e1^(e2-e3)
{1, 2, 3, 5, 6}
Conclusion : - est prioritaire devant ^
Conclusion finale :
Voici l'ordre des priorités des 4 opérateurs sur les ensembles :
1 : la différence -
2 : l'intersection &
3 : la différence symétrique ^
4 : l'union |
Dans une expression sans parenthèse utilisant plusieurs opérateurs, Python les interpréte dans l'ordre de leur priorité (et non dans l'ordre de l'expression).
Exemple : l'expression e1 | e2 & e3 ^ e4 - e5 sans parenthèse sera interprétée dans l'ordre suivant e1 | ( (e2 & e3) ^ (e4 - e5) )
L'inclusion
L'opérateur < représente le symbole de l'inclusion : e1<e2 est booléen (il vaut soit True soit False).
e1<e2 renvoie vrai si e1 est un sous-ensemble de e2, ce qui peut également s'écrire :
- e1 est une partie de e2
- tous les éléments de e1 sont présents dans e2
- e1 est inclus dans e2
>>> e1={3,8}
>>> e2={2,3,5,8}
>>> e1<e2
True
>>> e1={3,8,4}
>>> e1<e2
False
>>> {1,2}<{1,2,3}
True
>>> {1,5}<{1,2,3}
False
A retenir :
Les ensembles :
En Python, un ensemble est un type composé (contenant plusieurs éléments), modifiable et ne contenant pas de doublons.
La fonction set(x) permet de convertir l'objet x en ensemble
Une variable de type ensemble est utilisable avec les syntaxes rappelées dans le tableau suivant :
Syntaxe des ensembles en Python |
|
syntaxe |
commentaire |
{1,2,3,4} |
définition d'un ensemble entre accolades |
set() |
ensemble vide |
len(e) |
renvoie le nombre d'éléments contenus dans l'ensemble e |
set(x) |
convertit l'objet x en ensemble |
x in e |
teste si l'élément x appartient à l'ensemble e |
e.add(x) |
ajoute l'élément x dans l'ensemble e |
e.remove(x) |
supprime l'élément x de l'ensemble e |
e1&e2 |
intersection de deux ensembles e1 et e2 : ET |
e1|e2 |
union de deux ensembles e1 et e2 : OU |
e1^e2 |
différence symétrique de deux ensembles e1 et e2 : OU-Exclusif |
e1-e2 |
différence de deux ensembles e1 et e2 |
e1<e2 |
inclusion : renvoie vrai si e1 est un sous-ensemble de e2 |
e1<=e2 |
inclusion : renvoie vrai si e1 est un sous-ensemble de e2 ou si e1 et e2 sont égaux |
e1>e2 |
inclusion : renvoie vrai si e2 est un sous-ensemble de e1 |
e1>=e2 |
inclusion : renvoie vrai si e2 est un sous-ensemble de e1 ou si e2 et e1 sont égaux |
Les tuples
Les tuples sont des séquences d'objets non modifiables et s'écrivent entre parenthèses :
>>> t=(1,2,3,4)
>>> print(t)
(1, 2, 3, 4)
>>> type(t)
<class 'tuple'>
Les éléments d'un tuple sont accessibles par un index commençant à 0 et écrit entre crochets :
>>> t=(1,2,3,4)
>>> t[0]
1
>>> t[1]
2
>>> t[2]
3
>>> t[3]
4
Contrairement à une liste, un tuple est non modifiable. Si on essaye de modifier un élément dans le tuple après la création du tuple on obteint une erreur :
>>> t=(1,2,3,4)
>>> t[2]=6
Traceback (most recent call last):
File "<interactive input>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
Tout comme pour les chaînes de caractères ou les listes la fonction len permet de connaître le nombre d'éléments enregistrés dans un tuple :
>>> t=(1,2,3,4)
>>> len(t)
4
Tout comme pour les chaînes de caractères ou les listes l'opérateur in permet de tester si un élément appartient à un tuple ou pas :
>>> 2 in (1,2,3)
True
>>> 4 in (1,2,3)
False
Le tuple vide existe, il s'écrit () :
>>> t=()
>>> type(t)
<class 'tuple'>
>>> len(t)
0
Pour créer un tuple contenant un seul élément il faut faire suivre l'élément unique par une virgule afin que Python ne confonde pas le tuple avec une simple expression mathématique :
>>> t=(5,)
>>> type(t)
<class 'tuple'>
>>> len(t)
1
>>> print(t)
(5,)
Remarque : sans la virgule finale, l'expression (5) serait convertie naturellement en un nombre entier de valeur 5 (et non en un tuple) :
>>> t=(5)
>>> type(t)
<class 'int'>
>>> print(t)
5
Tout comme pour les chaînes de caractères ou les listes l'opérteur + permet de concaténer les tuples et permet de créer un tuple à partir d'autres :
>>> (1,2)+(3,4)
(1, 2, 3, 4)
>>> (7,8,9)+(10,)+(11,12)
(7, 8, 9, 10, 11, 12)
Tout comme pour les chaînes de caractères ou les listes l'opérteur * permet de multiplier un tuple et permet de générer rapidement un tuple répétitif :
>>> 7*(3,)
(3, 3, 3, 3, 3, 3, 3)
>>> 4*(1,2,3)
(1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3)
La fonction tuple() permet de convertir un objet en tuple :
>>> tuple([1,2,3,4])
(1, 2, 3, 4)
>>> tuple(range(10,20,2))
(10, 12, 14, 16, 18)
>>> tuple({'A','B','C'})
('A', 'C', 'B')
>>> tuple('bonjour')
('b', 'o', 'n', 'j', 'o', 'u', 'r')
Enfin il faut savoir que les paranthèses autour du tuple ne sont pas obligatoires lors de sa création :
>>> t=1,2,3
>>> type(t)
<class 'tuple'>
>>> t
(1, 2, 3)
>>> print(t)
(1, 2, 3)
A retenir :
Les tuples :
Les tuples sont des séquences d'objets écrites entre parenthèses, non modifiables, ordonnées et accessibles par un index
Les tuples sont comparables aux listes, la seule différence étant qu'un tuple est non modifiable
La fonction tuple(x) permet de convertir l'objet x en tuple
Les dictionnaires
Les dictionnaires sont des collections d'objets auquels on accède par une clé, et non par un index numérique. Voici un apperçu rapide de la syntaxe des dictionnaires en Python (toujours à tester dans la console) :
Création d'un dictionnaire vide :
>>> dico={}
>>> dico
{}
>>> type(dico)
<class 'dict'>
Remarque : le dictionnaire vide s'écrit {}, qui est bien un dictionnaire (et non un ensemble vide).
Dans un dictionnaire, chaque valeur enregistrée doit être référencée par une clé unique. Exemples :
Ajout de la valeur "dupont" avec la clé "nom" :
>>> dico["nom"]="dupont"
>>> dico
{'nom': 'dupont'}
Ajout d'autres éléments dans le dictionaire :
>>> dico["prénom"]="pierre"
>>> dico
{'nom': 'dupont', 'prénom': 'pierre'}
>>> dico["age"]=23
>>> dico
{'age': 23, 'nom': 'dupont', 'prénom': 'pierre'}
Affichage des éléments du dictionnaire :
>>> print(dico["prénom"],dico["nom"],"a",dico["age"],"ans.")
pierre dupont a 23 ans.
Création directe d'un dictionnaire contenant 3 éléments :
>>> dico={'nom':'durand','prenom':'paul','age':18}
>>> dico
{'age': 18, 'nom': 'durand', 'prenom': 'paul'}
La méthode keys() permet d'obtenir l'ensemble des clés du dictionnaire :
>>> dico.keys()
dict_keys(['nom', 'age', 'prenom'])
>>> list(dico.keys())
['nom', 'age', 'prenom']
La méthode values() permet d'obtenir l'ensemble des valeurs du dictionnaire :
>>> dico.values()
dict_values(['durand', 18, 'paul'])
>>> list(dico.values())
['durand', 18, 'paul']
L'opérateur in permet de tester si une clé est présente dans le dictionnaire :
>>> 'nom' in dico
True
>>> 'age' in dico
True
>>> 'adresse' in dico
False
>>> 'paul' in dico
False
La méthode items() renvoie les paires clé/valeur sous forme de tuples :
>>> dico.items()
dict_items([('nom', 'durand'), ('age', 18), ('prenom', 'paul')])
>>> list(dico.items())
[('nom', 'durand'), ('age', 18), ('prenom', 'paul')]
La méthode clear() vide le dictionaire :
>>> dico.clear()
>>> dico
{}
Appliquée à un dictionnaire, la fonction list renvoie la liste des clés :
>>> list({'a': 1, 'b': 2, 'c': 3})
['a', 'c', 'b']
Appliquée à un dictionnaire, la fonction len renvoie le nombre de paires clé/valeur enregistrées dans le dictionnaire :
>>> dico={'a': 1, 'b': 2, 'c': 3}
>>> len(dico)
3
>>> type(dico)
<class 'dict'>
A retenir :
Les dictionnaires :
En Python, un dictionnaire est un type composé (contenant plusieurs éléments), modifiable, et dont chaque valeur est référencée par une clé (et non par un index numérique). Un dictionniare peut être vu comme une collection de paires clé/valeur (appelée chacune "élément").
Syntaxe des dictionnaires en Python |
|
syntaxe |
commentaire |
{'a': 1, 'b': 2, 'c': 3} |
définition d'un dictionaire (ensemble de paires clé/valeur) |
{} |
dictionnaire vide (il ne contient aucune valeur) |
len(d) |
renvoie le nombre d'éléments contenus dans le dictionnaire d |
list(d) |
renvoie la liste des clés du dictionnaire d |
x in d |
teste si la clé x est présente dans le dictionnaire d |
d.keys() |
renvoie l'ensemble des clés du dictionnaire d |
d.values() |
renvoie l'ensemble des valeurs du dictionnaire d |
d.items() |
renvoie les paires clé/valeur du dictionnaire d sous forme de tuples |
d.clear() |
vide le dictionaire d (supprime tous ses éléments) |
Voici enfin pour récapitulatif la différence entre les 5 types composés de Python. On précise que :
- un type composé est ordonné si ses éléments sont directement accessibles par un index numérique commençant à 0
- un type composé peut contenir des doublons s'il est possible d'y enregistrer plusieurs fois la même valeur
- un type composé est modifiable si après sa création il est possible d'ajouter, supprimer ou modifier un ou plusieurs éléments
Comparaison des différents types composés |
|||
type |
ordonné |
peut contenir des doublons |
modifiable |
chaîne |
OUI |
OUI |
OUI |
liste |
OUI |
OUI |
OUI |
ensemble |
NON |
NON |
OUI |
tuple |
OUI |
OUI |
NON |
dictionnaire |
NON |
OUI |
OUI |
Rappel des 8 types à connaître :
Les 8 types de variables en Python |
||
type |
étiquette |
fonction de transtypage |
nombre entier |
int |
int() |
nombre décimal |
float |
float() |
booléen |
bool |
bool() |
chaîne de caractères |
str |
str() |
liste |
list |
list() |
ensemble |
set |
set() |
tuple |
tuple |
tuple() |
dictionnaire |
dict |
dict() |
Les fichiers
Le type "fichier" permet à Python d'accéder à des données par l'intermédiaire d'un fichier enregistré physiquement sur le disque dur.
Pour accéder à un fichier il existe 2 modes d'accès différents :
- le mode d'accès en lecture seule qui permet à Pyhton de lire simplement un fichier texte
- le mode d'accès en écriture qui permet à Python d'enregistrer des données dans un fichier
Accès à un fichier en lecture seule
Imaginons que nous disposions sur le disque dur d'un fichier texte nommé fichier.txt et dont le contenu est le suivant :
Ceci est un fichier texte
Il a été édité dans Edupython
Il est codé en UTF-8
Fin du fichier
Créez ce fichier texte dans EduPython (par un simple copier/coler des 4 lignes ci-dessus), enregistrez-le en UTF-8 dans votre répertoire de travail et réalisez les expériences suivantes dans la console de Python :
Pour accéder à un fichier il faut commencer par créer un descripteur de fichier avec la fonction open() de Python.
Le premier paramère de la fonction open() est le nom du fichier à lire, le second est 'r' pour 'lecture seule' (read) :
fic=open('fichier.txt','r')
On obtient alors un descripteur de fichier (nomé ici fic) qui est un objet contenant différentes méthodes permettant d'accéder au fichier.
Parmi ces méthodes, la méthode read() renvoie tout le fichier sous forme d'une chaîne de caractères unique :
>>> s=fic.read()
>>> s
'Ceci est un fichier texte\nIl a été édité dans Edupython\nIl est codé en UTF-8\nFin du fichier\n\n'
La méthode readlines() lit tout le fichier et renvoie une liste contenant chacune des lignes :
>>> fic=open('fichier.txt','r')
>>> liste=fic.readlines()
>>> liste
['Ceci est un fichier texte\n',
'Il a été édité dans Edupython\n',
'Il est codé en UTF-8\n',
'Fin du fichier\n',
'\n']
La méthode close() permet de fermer le fichier correctement après son utilisation :
fic.close()
Voici quelques problèmes possibles (et leurs solutions à connaître) lors de la lecture d'un fichier texte en Python :
Problème 1 : le fichier n'est pas trouvé par Python :
>>> fic=open('fichier.txt','r')
Traceback (most recent call last):
File "<interactive input>", line 1, in <module>
IOError: [Errno 2] No such file or directory: 'fichier.txt'
Dans ce cas il faut indiquer à Python le répertoire courant dans lequel le fichier est enregistré. Pour cela il faut importer le module os de Python permettant de connaître et de modifier le répertoire courant :
>>> import os
>>> os.getcwd()
'C:\\Program Files\\EduPython'
>>> os.chdir('c:\python')
>>> os.getcwd()
'c:\\python'
La méthode getcwd() du module os permet de connaître le répertoire courant dans lequel Python recherchera les fichiers.
La méthode chdir() du module os permet de changer le répertoire courant.
A retenir : avant de vouloir lire un fichier en Python il faut changer le répertoire courant avec la fonction chdir() du module os pour indiquer l'emplacement du fichier à lire
Et voici le programme complet qui affiche le contenu du fichier texte fichier.txt après avoir changé de répertoire courant :
# Lecture d'un fichier texte
# importe le module os :
import os
# configure le répertoire courant contenant le fichier à lire :
os.chdir('p:\\Mes documents\\nsi\\python\\fichier')
# affiche le répertoire courant :
print('Le répertoire courant est %s ' % os.getcwd())
# ouvre le fichier en lecture seule et cré un nouvel objet nommé fic :
fic=open('fichier.txt','r')
# lit le fichier et enregistre son contenu dans la chaîne de caractères s :
s=fic.read()
# referme le fichier après la lecture :
fic.close()
# affiche le contenu du fichier dans la console :
print(s)
Remarque : pour configurer le chemin p:\Mes documents\nsi\python\fichier comme répertoire courant, il faut doubler les anti-slash en le passant en paramètre à la fonction os.chdir() :
os.chdir('p:\\Mes documents\\nsi\\python\\fichier')
Problème 2 : à la lecture du fichier on constate des erreurs d'encodage des caractères :
Le fichier texte est enregistré en utilisant un certain jeu de caractères (en principe ANSI ou UTF-8).
Mais par défaut à la lecture brute du fichier, Python lira une suite d'octets sans les interpréter en tant que codes UTF-8.
Il conviendra alors de procéder parfois à un transcodage, en utilisant les fonctions appropriées et vues dans le traitement et l'encodage des chaînes de caractères.
Mais pour éviter des problèmes d'encodage des caractères accentués, le plus simple en un premier temps est d'encoder le fichier texte en ANSI. Dans EduPython on configure le jeu de caractères utilisé pour enregistrer un fichier texte en allant dans le sous-menu Format de fichier dans le menu Edition :
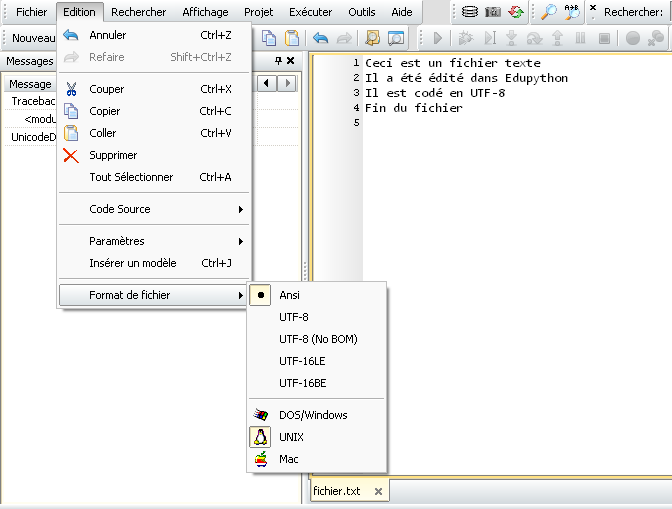
Si le fichier texte à lire est encodé en ANSI, alors la lecture des caractères accentués est directe et ne pose pas de problèmes particuliers :
fic=open('fichier.txt','r')
s=fic.readlines()
print(s)
fic.close()
Et voici le résultat affiché dans la console de Python :
['Ceci est un fichier texte\n', 'Il a été édité dans Edupython\n', 'Il est codé en ANSI\n', 'Fin du fichier\n']
Si maintenant le fichier texte est encodé en UTF-8, un décodage suplémentaire est nécessaire.
Tout d'abord dans EduPython il fait configurer consciemment en UTF-8 le format de fichier avant de l'enregistrer :
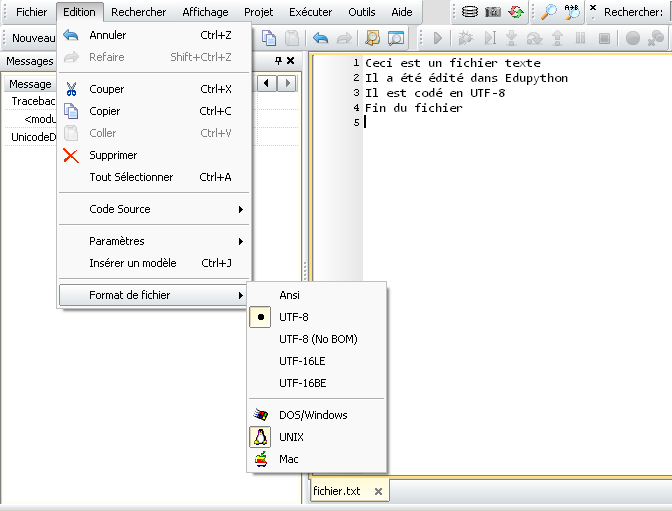
Ensuite il faut procéder à une succession de transcodage et de "nettoyage" des données lues, en lisant le fichier texte en tant que fichier binaire (paramètre 'rb' dans open) :
fic=open('fichier.txt','rb')
s=fic.read().decode()[1:].splitlines()
print(s)
fic.close()
Et voici le résultat affiché dans la console de Python :
['Ceci est un fichier texte', 'Il a été édité dans Edupython', 'Il est codé en UTF-8', 'Fin du fichier']
A retenir : avant de vouloir lire un fichier en Python il faut savoir avec quel jeu de caractères il a été encodé. Pour configurer l'encodage d'un fichier texte dans EduPython il faut aller dans Edition + Format de fichier.
Par défaut, la fonction open() de Python utilise donc le jeu de caractères ANSI (page de code utilisée par Windows) lors de l'ouverture d'un fichier texte.
Rappel concernant le jeu de caractères ANSI :
- le nom exact du jeu de caractères ANSI est cp1252 (page de code n°1252, utilisée par Windows)
- les pages de code latin1, latin_1, iso8859 ou encore iso8859-15 toutes utilisables dans Python sont "similaires" à la page de code cp1252
Mais on peut préciser à la fonction open() le jeu de caractères à utiliser pour décoder le fichier texte lors de sa lecture. Pour cela il faut ajouter un 3ème paramètre (en plus du nom du fichier et du mode d'accès) de la forme encoding=''
Les 6 lignes suivantes ouvrent toutes le fichier en considérant qu'il est encodé en ANSI, et sont donc pratiquement équivalentes :
fic=open('fichier.txt','r',encoding='cp1252')
fic=open('fichier.txt','r',encoding='latin1')
fic=open('fichier.txt','r',encoding='latin_1')
fic=open('fichier.txt','r',encoding='iso8859')
fic=open('fichier.txt','r',encoding='iso8859-15')
fic=open('fichier.txt','r')
La page de code utilisée par défaut par la fonction open() est cp1252 : en l'absence du paramètre endoding les octets du fichier texte seront décodés par le jeu de caractères cp1252 (appelé ANSI dans EduPython et dans Windows).
Si maintenant on veut ouvrir un fichier texte qui est endocé en UTF-8, sans vouleur "décoder à la main" des octets lus, il suffit de préciser à la fonction open() que le fichier est encodé en UTF-8. La ligne à utiliser est alors la suivante :
fic=open('fichier.txt','r',encoding='utf-8')
Repartons avec le fichier fichier.txt encodé en UTF-8 dans EduPython :
En précisant encoding='utf-8' en paramètre de la fonction open() la lecture du fichier est désormais directe sans problème de décodage des caractères accentués :
# lecture d'un fichier texte en UTF-8 :
fic=open('fichier.txt','r',encoding='utf-8')
s=fic.readlines()
print(s)
fic.close()
Et voici le résultat affiché dans la console de Python :
['\ufeffCeci est un fichier texte\n', 'Il a été édité dans Edupython\n', 'Il est codé en UTF-8\n', 'Fin du fichier\n']
On remarque que le premier caractère du fichier est le caractère unicode de point de code U+FEFF (il s'agit d'un espace insécable). En effet, tout fichier texte codé en UTF-8 commencera toujours par les 3 octets \xef\xbb\xbf (codage en UTF-8 du caractère unicode de point de code U+FEFF indiquant que le fichier est encodé en UTF-8) avant les caractères enregistrés dans le fichier. Il convient alors de supprimer ce caractère U+FEFF au début de la première ligne, par exemple en affichant les caractères à partir du n°1 (et non du n°0 qui est U+FEFF) :
fic=open('fichier.txt','r',encoding='utf-8')
s=fic.read()
print(s[1:])
fic.close()
Et voici le résultat affiché dans la console de Python :
Ceci est un fichier texte
Il a été édité dans Edupython
Il est codé en UTF-8
Fin du fichier
En testant la valeur des 3 premiers octets d'un fichier il est alors possible de déterminé si le fichier est encodé en UTF-8 ou pas :
# test des 3 premiers octets d'un fichier binaire :
fic=open('fichier.txt','rb')
bin=fic.read()
debut=bin[0:3]
if debut==b'\xef\xbb\xbf':
print('Ce fichier est encodé en UTF-8')
else:
print("Ce fichier n'est pas encodé en UTF-8 (sans doute en ANSI)")
fic.close()
Remarque : l'encodage utf-8 peut également s'écrire utf8 en Python (sans le trait d'union). Les 2 lignes suivantes sont donc identiques :
fic=open('fichier.txt','r',encoding='utf8')
fic=open('fichier.txt','r',encoding='utf-8')
A retenir : un fichier texte encodé en UTF-8 commence toujours par le caractère unicode de point de code U+FEFF (espace insécable indiquant que l'encodage du fichier est UTF-8). Pour ouvrir en Python un fichier texte encodé en UTF-8 il faut rajouter le paramètre encoding='utf8' lors de l'appel de la fonction open().
Lecture d'une partie d'un fichier texte
Nous partons du fichier texte suivant nommé fichier.txt, contenant 3 lignes et encodé en ANSI :
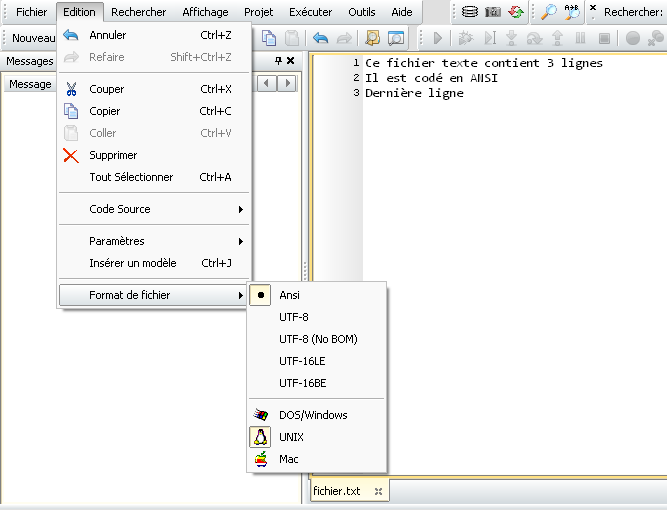
Créez ce fichier texte et réalisez les expériences suivantes dans la console de Python :
Ouvrons le fichier dans la console en y connectant le descripteur fic :
>>> fic=open('fichier.txt','r')
Appelons la méthode read() de l'objet fic afin de lire tout le fichier :
>>> fic.read()
On obtient en retour les 3 lignes, c'est-à-dire le fichier complet :
'Ce fichier texte contient 3 lignes\nIl est codé en ANSI\nDernière ligne'
Remarque : les retours à la ligne sont représentés par le caractère ASCII \n de code 10 :
>>> ord('\n')
10
Essayons de relire le fichier en appellant à nouveau la méthode read() :
>>> fic.read()
Et là on obtient une chaîne vide :
''
Explication : lorsque Python accède à un fichier il utilise pour se repérer dans le fichier "un curseur" correspondant à la position courante de lecture dans le fichier.
Juste après l'ouverture du fichier par open() le curseur est en position 0, c'est-à-dire au début du fichier.
Après la lecture complère du fichier le curseur est en position finale, c'est-à-dire à la fin du fichier.
Or la méthode read() renvoie le texte compris entre la position courante du curseur et la fin du fichier.
Pour régler la position du curseur il faut utiliser la méthode seek() liée au descripteur de fichier fic. Par exemple pour remettre le curseur au début du fichier il faut appeler fic.seek(0) :
>>> fic.seek(0)
0
>>> fic.read()
'Ce fichier texte contient 3 lignes\nIl est codé en ANSI\nDernière ligne'
Sans paramètre particulier, la méthode read() renvoie tout le texte compris entre la position courante du curseur et la fin du fichier.
Si on veut lire seulement quelques caractères dans le fichier on peut alors passer en paramètre à la méthode read() le nombre de caractères à lire. Par exemple fic.read(16) pour lire seulement 16 caractères :
>>> fic.seek(0)
0
>>> fic.read(16)
'Ce fichier texte'
Nous venons de lire 16 caractères à partir du début du fichier. Le curseur, initialement placé en position 0 par seek(0) a donc avancé de 16 positions. Quelle est donc actuellement sa position courante ? Pour connaître la position courante du curseur de lecture dans un fichier sans la modifier il faut faire appel à la méthode tell() :
>>> fic.tell()
16
Sans surprise le curseur est actuellement en position 16. Cela signifie que la prochaine lecture avec read() partira de la position 16.
Lisons maintenant 18 caractères : on obtient alors les 18 caractères suivant dans le fichier (à partir de la position 16) :
>>> fic.read(18)
' contient 3 lignes'
Voici pour rappel le contenu de notre fichier texte :
Ce fichier texte contient 3 lignes\n
Il est codé en ANSI\n
Dernière ligne
Comment extraire la chaîne de caractères 'codé en ANSI' à partir de ce fichier texte ? Notre chaîne contenant 12 caractères à partir de la position 42 il suffit de positionner le curseur sur le caractère n°42 avec seek(42) puis de demander la lecture de 12 caractères seulement avec read(12) :
>>> fic.seek(42)
42
>>> fic.read(12)
'codé en ANSI'
Problème : comment obtenir seulement les 2 dernières lignes du fichier sachant que la première ligne a une taille de 35 caractères ?
Solution : on déplace le curseur en position 35 puis on lit tout le fichier de cette position jusqu'à la fin du fichier :
>>> fic.seek(35)
35
>>> fic.read()
'Il est codé en ANSI\nDernière ligne'
Ne pas oublier à la fin du traitement de fermer le fichier par la méthode close() :
>>> fic.close()
A retenir :
- la méthode read(n) renvoie n caractères à partir de la position courante du curseur
- la méthode seek(n) déplace le curseur en position n
- la méthode tell() renvoie la position courante du curseur sans la modifier
Accès à un fichier en écriture
Pour accéder à un fichier en écriture il faut préciser 'w' en second paramètre de la fonction open() (w pour write) :
fic=open('fichier_neuf.txt','w')
La méthode write() de l'objet fic permet alors d'écrire dans le nouveau fichier nommé ici fichier_neuf.txt :
>>> fic.write('Bonjour')
7
Remarque : la méthode write() renvoi le nombre d'octet écrit dans le fichier.
Pour que les données soient réellement écrite sur le disque dur il faut bien fermer le fichier par la méthode close() :
>>> fic.close()
Voici à cet instant le contenu du fichier fichier_neuf.txt :
Bonjour
Pour ajouter du texte à la fin du fichier il faut le ré-ouvrir avec le paramère 'a' (pour ajouter) et non avec 'w' qui écraserait le fichier existant :
fic=open('fichier_neuf.txt','a')
Ajoutons du texte à la fin du fichier :
>>> fic.write('Au revoir')
9
Fermons le fichier :
>>> fic.close()
Voici à cet instant le contenu du fichier fichier_neuf.txt :
BonjourAu revoir
On constate que la méthode write() associées aux fichiers écrit chaque chaîne de caractères dans le fichier sans insérer de retour à la ligne.
Pour séparer physiquement chaque ligne dans le fichier il faut insérer un caractère '\n' à la fin de chaque chaîne de caractères.
La méthode writelines() permet d'écrire dans le fichiers tous les éléments d'une liste. Démonstration :
Créons un nouveau fichier en écrasant le fichier existant (paramètre 'w') :
fic=open('fichier_neuf.txt','w')
Créons une liste à 3 éléments (des chaînes de caractère finissant par '\n') :
>>> liste=['Bonjour\n','Ceci est un fichier texte fait par Python\n','Fin du fichier\n']
Écrivons chacune de ces 3 lignes dans le fichier avec un seul appel à la méthodes writelines() :
>>> fic.writelines(liste)
Fermons le fichier :
>>> fic.close()
Voici à cet instant le contenu du fichier fichier_neuf.txt :
Bonjour
Ceci est un fichier texte fait par Python
Fin du fichier
Remarque : par défaut la méthode write() de Python utilise l'encodage ANSI pour écrire dans un fichier texte :
fic=open('fic.txt','w')
fic.write('Ce fichier a été créé par Python\n')
fic.write('Il est encodé en ANSI par défaut\n')
fic.close()
fic=open('fic.txt','r')
s=fic.readlines()
fic.close()
print(s)
Et voici le résultat affiché dans la console :
['Ce fichier a été créé par Python\n', 'Il est encodé en ANSI par défaut\n']
Si on écrit des chaînes de caractères accentuées dans un fichier texte, leur relecture ne nécessite aucun décodage particulier.
A retenir : le jeu de caractères utilisé par défaut par Python pour écrire dans un fichier texte est ANSI, qui est l'encodage à utiliser en priorité pour éviter des problèmes avec les caractères accentués
Grâce à la fonction open() de Python et aux méthodes read(), write() et close() liées aux descripteurs de fichiers vous savez désormais lire et écrite dans un fichier texte à partir d'un programme en Python afin d'enregistrer des données de manière durable sur le disque dur.
Site Internet : python.gecif.net Auteur : Jean-Christophe MICHEL Professeur de Sciences Industrielles de l'Ingénieur Courriel : jc.michel@gecif.net |