| ACCUEIL | Les chaînes de caractères | DECOUVERTE | APPLICATION | EVALUATION |
Les chaînes de caractères

Manipulation de base des chaînes de caractères
Tous les exemples suivants sont à tester dans la console d'EduPython afin de découvrir la manipulation des chaînes de caractères en Python.
Écriture et affichage d'une chaîne de caractères
Une chaîne de caractères est une suite de caractères représentant un message et encadrée par le caractère "double quote" :
>>> chaine="Ceci est une chaîne de caractères"
La fonction print de Python permet d'afficher une chaîne de caractères :
>>> print(chaine)
Ceci est une chaîne de caractères
Les opérateurs agissant sur les chaînes de caractères
L'opérateur + permet de concaténer plusieurs chaînes de caractères, c'est-à-dire de les rassembler pour n'en former plus qu'une :
>>> ch1="Python permet"
>>> ch2=" de manipuler"
>>> ch3=" facilement les chaînes"
>>> ch4=" de caractères"
>>> message=ch1+ch2+ch3+ch4
>>> print(message)
Python permet de manipuler facilement les chaînes de caractères
Autre exemple de concaténation de deux chaînes de caractères avec l'opérateur + :
>>> "Ceci "+"est une chaîne"+" de caractères"
'Ceci est une chaîne de caractères'
>>> s1="Voici un"
>>> s2=" message composé "
>>> s3="de 3 chaînes"
>>> print(s1,s2,s3)
Voici un message composé de 3 chaînes
>>> print(s1+s2+s3)
Voici un message composé de 3 chaînes
L'opérateur * permet de multiplier plusieurs fois une chaîne de caractères, c'est-à-dire de la répéter à l'identique :
>>> "ABC" * 3
'ABCABCABC'
>>> "_*" * 20
'_*_*_*_*_*_*_*_*_*_*_*_*_*_*_*_*_*_*_*_*'
>>> "bla" * 2
'blabla'
L'opérateur in permet de tester si une chaîne est comprise dans une autre chaîne. C'est un opérateur booléen qui renvoie soit Vrai (True) soit Faux (False) :
>>> "n" in "Bonjour"
True
>>> "z" in "Bonjour"
False
>>> "Python" in "Le langage Python permet de manipuler des chaînes de caractères"
True
>>> "python" in "Le langage Python permet de manipuler des chaînes de caractères"
False
Accès direct à une partie d'une chaîne de caractères
L'accès direct à un caractère se fait en l'indexant à partir de 0 en précisant un indice entre crochets :
>>> s="Python"
>>> s[0]
'P'
>>> s[1]
'y'
>>> s[2]
't'
Un index négatif part de la fin de la chaîne (s[-1] étant le dernier caractère) :
>>> s[-1]
'n'
>>> s[-2]
'o'
>>> s[-3]
'h'
Il est possible de définir une "tranche" de la chaîne en utilisant le caractère deux points dans l'indice indiqué entre crochets. Exemples :
Les caractères du début au 3 (non compris) :
>>> s[:3]
'Pyt'
Les caractères du 3 (compris) à la fin de la chaîne :
>>> s[3:]
'hon'
Les caractères 1 (compris) à 4 (non compris) :
>>> s[1:4]
'yth'
Les caractères 0 (compris) à 5 (non compris) par pas de 2 (un sur 2) :
>>> s[0:5:2]
'Pto'
Traitement des chaînes de caractères
Voici quelques méthodes ou fonctions pratiques appliquées sur une chaîne de caractères :
Longueur d'une chaîne de caractères
La fonction len permet de connaître le nombre de caractères d'une chaîne :
>>> len("ABC")
3
>>> s="Python permet de manipuler facilement les chaînes de caractères"
>>> len(s)
63
Comptage d'un caractère particulier
La méthode count permet de savoir combien de fois un caractère (ou une sous-chaîne) est présent dans la chaîne :
>>> s="Python permet de manipuler facilement les chaînes de caractères"
>>> s.count("h")
2
>>> s.count("m")
3
>>> s.count("de")
2
>>> s.count("facile")
1
>>> s.count("orange")
0
>>> s.count(" ")
8
Recherche de la position d'un caractère particulier
La méthode index permet de savoir à quelle position se trouve un caractère particulier ou une sous-chaîne :
>>> s="Python permet de manipuler facilement les chaînes de caractères"
>>> s.index("e")
8
>>> s.index("er")
8
>>> s.index("em")
32
Remarque : si la sous-chaîne recherchée n'existe pas dans la chaîne analysé, alors la méthode index renvoie une erreur :
>>> s="Python permet de manipuler facilement les chaînes de caractères"
>>> s.index("zoro")
Traceback (most recent call last):
File "<interactive input>", line 1, in <module>
ValueError: substring not found
Recherche de la position d'une sous-chaîne dans la chaîne
La méthode find permet de savoir à quelle position se trouve un caractère particulier ou une sous-chaîne :
>>> s="Python permet de manipuler facilement les chaînes de caractères"
>>> s.find("e")
8
>>> s.find("er")
8
>>> s.find("em")
32
>>> s.find("zoro")
-1
Remarque : si la sous-chaîne recherchée n'existe pas dans la chaîne analysée, alors la méthode find renvoie la valeur -1 sans provoquer d'erreur. Pour cette raison la méthode find est préférable à la méthode index mais les deux sont à connaître.
Remplacement d'un caractère par un autre
La méthode replace permet de remplacer un caractère par un autre sur l'ensemble de la chaîne.
Remplaçons par exemple tous les caractères "espace" par des caractères "underscore" :
>>> s="Python permet de manipuler facilement les chaînes de caractères"
>>> s.replace(" ","_")
'Python_permet_de_manipuler_facilement_les_chaînes_de_caractères'
>>> s
'Python permet de manipuler facilement les chaînes de caractères'
Remarque : la chaîne renvoyée est bien la chaîne d'origine avec les caractères substitués, mais la chaîne s d'origine n'a pas été modifiée.
Pour conserver la nouvelle chaîne après la transformation il faut l'enregistrer dans une nouvelle variable :
>>> s1="Python permet de manipuler facilement les chaînes de caractères"
>>> s2=s1.replace(" ","_")
>>> s1
'Python permet de manipuler facilement les chaînes de caractères'
>>> s2
'Python_permet_de_manipuler_facilement_les_chaînes_de_caractères'
La méthode replace permet de remplacer toute une sous-chaîne (et pas seulement un seul caractère à la fois) :
>>> s1="Python permet de manipuler facilement les chaînes de caractères"
>>> s2=s1.replace("manipuler","tansformer")
>>> s2
'Python permet de tansformer facilement les chaînes de caractères'
Remarque : si la sous-chaîne recherchée n'existe pas, la méthode replace renverra la chaîne d'origine non transformée et sans provoquer d'erreur :
>>> s1="Python permet de manipuler facilement les chaînes de caractères"
>>> s2=s1.replace("zoro","héro")
>>> s2
'Python permet de manipuler facilement les chaînes de caractères'
Découpage d'une chaîne de caractères
La méthode split permet de découper une chaîne selon un séparateur particulier et renvoie le résultat dans une liste.
Par exemple si on découpe la chaîne selon le caractère "espace", on obtient la liste des mots :
>>> s="Python permet de manipuler facilement les chaînes de caractères"
>>> s.split(' ')
['Python',
'permet',
'de',
'manipuler',
'facilement',
'les',
'chaînes',
'de',
'caractères']
Remarque : en Python une liste est une série d'éléménts écrits entre crochets et séparés par une virgule. Exemple : [1,2,3,4] est une liste
On peut découper la chaîne selon n'importe quel caractère séparateur. Par exemple le caractère "a" :
>>> s="Python permet de manipuler facilement les chaînes de caractères"
>>> s.split('a')
['Python permet de m',
'nipuler f',
'cilement les ch',
'înes de c',
'r',
'ctères']
Remarque : le caractère séparateur n'est plus présent dans la liste obtenue.
On peut également découper la chaîne selon une sous-chaîne. Par exemple la sous-chaîne " de " :
>>> s="Python permet de manipuler facilement les chaînes de caractères"
>>> s.split(' de ')
['Python permet', 'manipuler facilement les chaînes', 'caractères']
Enfin, si on veut conserver la liste générée il faut l'enregistrer dans une variable :
>>> s="Python permet de manipuler facilement les chaînes de caractères"
>>> liste=s.split(" ")
>>> print(liste)
['Python', 'permet', 'de', 'manipuler', 'facilement', 'les', 'chaînes', 'de', 'caractères']
Jointure d'une liste ou d'une chaîne de caractères
La méthode join permet de joindre les différents éléments d'une liste en utilisant une chaîne comme séparateur et renvoie le résultat dans une chaîne de caractères.
Par exemple si on joint la liste ['A','B','C'] avec la chaîne '#' on obtient la chaîne 'A#B#C' :
>>> '#'.join(['A','B','C'])
'A#B#C'
Autre exemple : pour obtenir la chaîne 'il fait beau' à partir de la liste de mots ['il','fait','beau'] il faut utiliser un espace comme séparateur. La jointure s'écrit alors :
>>> ' '.join(['il','fait','beau'])
'il fait beau'
On vient de voir la jointure appliquée à une liste, mais la jointure peut aussi s'appliquer à une chaîne de caractères. Voici quelques exemples à tester :
>>> '+'.join('123456')
'1+2+3+4+5+6'
>>> ' et '.join('ABCDE')
'A et B et C et D et E'
>>> '123'.join('456')
'412351236'
Trie d'une chaîne de caractères
La fonction sorted permet de trier une chaîne de caractères dans l'ordre croissant. Elle renvoie une liste dans laquelle les caractères sont rangés dans l'ordre croissant :
>>> sorted("571643")
['1', '3', '4', '5', '6', '7']
>>> sorted("DAECB")
['A', 'B', 'C', 'D', 'E']
>>> sorted("et, voici, un dernier exemple !")
[' ',
' ',
' ',
' ',
' ',
'!',
',',
',',
'c',
'd',
'e',
'e',
'e',
'e',
'e',
'e',
'i',
'i',
'i',
'l',
'm',
'n',
'n',
'o',
'p',
'r',
'r',
't',
'u',
'v',
'x']
Majuscules et minuscules
Voici 4 méthodes permettant de convertir des lettres majuscules en lettres minuscules ou inversement.
La méthode upper permet de convertir en majuscules la totalité des lettres (accentuées ou pas) d'une chaîne de caractères, que les lettres soient en majuscules ou en minuscules dans la chaîne d'origine :
>>> s="Python permet de manipuler facilement les chaînes de caractères"
>>> s.upper()
'PYTHON PERMET DE MANIPULER FACILEMENT LES CHAÎNES DE CARACTÈRES'
Remarque : les caractères non alphabétiques (chiffres, caractères de ponctuation, etc.) sont inchangés par la méthodes upper :
>>> s="Dans l'addition 2+3=5, le caractère + est un opérateur et le résultat 5 est appelé 'la somme'."
>>> s.upper()
"DANS L'ADDITION 2+3=5, LE CARACTÈRE + EST UN OPÉRATEUR ET LE RÉSULTAT 5 EST APPELÉ 'LA SOMME'."
La méthode capitalize convertit en majuscule la première lettre d'une chaîne de caractères, et en minuscules la totalité des autres :
>>> s="le langage de programmation Python permet de manipuler facilement les chaînes de caractères"
>>> s.capitalize()
'Le langage de programmation python permet de manipuler facilement les chaînes de caractères'
Quelque soit la casse (minuscule ou majuscule) des lettres dans la chaîne d'origine, seule la première lettre est mise en majuscule par la méthode capitalize :
>>> s="le soleil"
>>> s.capitalize()
'Le soleil'
>>> s="LE SOLEIL"
>>> s.capitalize()
'Le soleil'
>>> s="Le Soleil"
>>> s.capitalize()
'Le soleil'
>>> s="le SOLEIL"
>>> s.capitalize()
'Le soleil'
Remarque : les caractères non alphabétiques (chiffres, caractères de ponctuation, etc.) sont inchangés par la méthodes capitalize :
>>> s="dans l'addition 2+3=5, le caractère + est un opérateur et le résultat 5 est appelé 'la somme'."
>>> s.capitalize()
"Dans l'addition 2+3=5, le caractère + est un opérateur et le résultat 5 est appelé 'la somme'."
La méthode title permet de convertir en majuscule la première lettre de chaque mot d'une chaîne :
>>> s="python permet de manipuler facilement les chaînes de caractères"
>>> s.title()
'Python Permet De Manipuler Facilement Les Chaînes De Caractères'
En cas de mot composés (contenant un trait d'union), les initiales des 2 mots sont converties en majuscule par la méthode title :
>>> s="on appelle sous-chaîne un ensemble consécutif de caractères compris dans une chaîne"
>>> s.title()
'On Appelle Sous-Chaîne Un Ensemble Consécutif De Caractères Compris Dans Une Chaîne'
Remarque : les caractères non alphabétiques (chiffres, caractères de ponctuation, etc.) sont inchangés par la méthodes title :
>>> s="dans l'addition 2+3=5, le caractère + est un opérateur et le résultat 5 est appelé 'la somme'."
>>> s.title()
"Dans L'Addition 2+3=5, Le Caractère + Est Un Opérateur Et Le Résultat 5 Est Appelé 'La Somme'."
La méthode swapcase permet d'inverser la casse (minuscule/majuscule) de tous les caractères alphabétiques d'une chaîne :
>>> s="Python permet de manipuler facilement les chaînes de caractères"
>>> s.swapcase()
'pYTHON PERMET DE MANIPULER FACILEMENT LES CHAÎNES DE CARACTÈRES'
Toutes les lettres, y compris les lettres accentuées, ont leur casse modifiée par la méthodes swapcase :
>>> s="la méthode SWAPCASE de Python bascule la CASSE (majuscule/minuscule) de toutes les LETTRES de la chaîne"
>>> s.swapcase()
'LA MÉTHODE swapcase DE pYTHON BASCULE LA casse (MAJUSCULE/MINUSCULE) DE TOUTES LES lettres DE LA CHAÎNE'
Remarque : les caractères non alphabétiques (chiffres, caractères de ponctuation, etc.) sont inchangés par la méthodes swapcase :
>>> s="Dans l'addition 2+3=5, le caractère + est un OPÉRATEUR et le résultat 5 est appelé 'la somme'."
>>> s.swapcase()
"dANS L'ADDITION 2+3=5, LE CARACTÈRE + EST UN opérateur ET LE RÉSULTAT 5 EST APPELÉ 'LA SOMME'."
D'autres méthodes avancées non vues ici sont applicables à un objet chaîne de caractères.
Conversion des chaînes de caractères
La fonction str permet de convertir en chaîne de caractère un objet quelconque :
>>> str(56)
'56'
Par exemple si n est un nombre entier, str(n) renvoie une chaîne de caractères composée des chiffres de n :
>>> n=2019
>>> ch=str(n)
>>> print(n)
2019
>>> print(ch)
2019
>>> n
2019
>>> ch
'2019'
Attention : dans l'exemple précédent n est une variable de type nombre entier, et ch est une variable de type chaîne de caractères composée des caractères 2, 0, 1 et 9.
La fonction str permet également de convertir en chaîne de caractères un nombre décimal. Exemples :
>>> str(3.14)
'3.14'
>>> str(1234.56789)
'1234.56789'
>>> str(5+7.6)
'12.6'
Remarque : la fonction str peut également s'appliquée sur une liste :
>>> liste=["A","B","C"]
>>> str(liste)
"['A', 'B', 'C']"
La fonction list peut convertir en liste une chaîne de caractères :
>>> list("Bonjour")
['B', 'o', 'n', 'j', 'o', 'u', 'r']
On obtient alors une liste dont chaque élément est un caractère de la chaîne d'origine :
>>> list("Il était une fois")
['I',
'l',
' ',
'é',
't',
'a',
'i',
't',
' ',
'u',
'n',
'e',
' ',
'f',
'o',
'i',
's']
>>> list("2+3=5")
['2', '+', '3', '=', '5']
Les différents délimitateurs encadrant une chaîne de caractères
Les chaînes de caractères peuvent être encadrées par 4 délimitateurs différents :
- la simple quote ' (permet d'écrire des doubles quotes dans la chaîne de caractères)
- la double quote " (permet d'écrire des simples quotes dans la chaîne de caractères)
- la triple simple quote ''' (permet d'écrire une chaîne de caractères sur plusieurs lignes)
- la triple double quote """ (permet d'écrire une chaîne de caractères sur plusieurs lignes)
Exemples :
>>> "Bonjour"
'Bonjour'
>>> "Ceci est une chaîne contenant des 'simples quotes' dans ces caractères"
"Ceci est une chaîne contenant des 'simples quotes' dans ces caractères"
>>> 'Ceci est une chaîne contenant des "doubles quotes" dans ces caractères'
'Ceci est une chaîne contenant des "doubles quotes" dans ces caractères'
>>> """Ceci est une chaîne
... de caractères contenant
... des retours à la ligne"""
'Ceci est une chaîne\nde caractères contenant\ndes retours à la ligne'
Remarque : les retours à la ligne sont codés \n dans la chaîne de caractères.
>>> """Voici une chaîne contenant à la fois des 'simples' et des "doubles" quotes"""
'Voici une chaîne contenant à la fois des \'simples\' et des "doubles" quotes'
Remarque : les simples quotes sont codés \' dans la chaîne de caractères si la chaîne est encadrée par des simples quotes.
Si on veut écrire à la fois des simples quotes et des doubles quotes dans une chaîne de caractères il faut l'encadrer par des 'triples simples quotes' ou des "triples doubles quotes" :
>>> '''Voici une chaîne de caractères contenant à la fois des 'simples quotes' et des "doubles quotes"'''
'Voici une chaîne de caractères contenant à la fois des \'simples quotes\' et des "doubles quotes"'
Formatage d'une chaîne de caractères
Appliqué à une chaîne de caractères, l'opérateur % permet de "formater" la chaîne, c'est-à-dire d'y insérer des valeurs à des endroits précis afin de former facilement un message complexe.
Tous les motifs %s présents dans la chaîne sont remplacés par les valeurs passées à droite du symbole % :
>>> "Voici un %s exemple" % ("premier")
'Voici un premier exemple'
Il peut y avoir plusieurs valeurs à insérer dans la chaîne qui contient alors plusieurs motifs %s :
>>> "%s permet de %s facilement les %s de caractères" % ("Python","formater","chaînes")
'Python permet de formater facilement les chaînes de caractères'
Les valeurs de remplacement peuvent être des nombres (entiers ou décimaux) :
>>> "Ces %s articles coûtent %s euros" % (3,8.25)
'Ces 3 articles coûtent 8.25 euros'
Les valeurs de remplacement peuvent être des variables :
>>> nom="Maxime"
>>> age=17
>>> moyenne=18.2
>>> "%s qui a %s ans a une moyenne de %s/20" % (nom,age,moyenne)
'Maxime qui a 17 ans a une moyenne de 18.2/20'
Pour forcer un nombre à s'afficher en nombre entier il faut utiliser le motif %d à la place de %s :
>>> "%s -----> %d" % (7.256,7.256)
'7.256 -----> 7'
Pour forcer un nombre à s'afficher en nombre décimal il faut utiliser le motif %f à la place de %s :
>>> "%s -----> %f" % (81,81)
'81 -----> 81.000000'
L'avantage du motif %f est qu'on peut préciser le nombre de chiffres après la virgule que l'on veut afficher :
>>> pi=3.14159265358979
>>> "Pi = %f" % (pi)
'Pi = 3.141593'
>>> "Pi avec 2 chiffres après la virgule : %.2f" % (pi)
'Pi avec 2 chiffres après la virgule : 3.14'
>>> "Pi avec 8 chiffres après la virgule : %.8f" % (pi)
'Pi avec 8 chiffres après la virgule : 3.14159265'
>>> "Pi avec 1 chiffre après la virgule : %.1f" % (pi)
'Pi avec 1 chiffre après la virgule : 3.1'
On constate que par défaut le motif %f affiche 6 chiffres après la virgule.
En résumé, dans une chaîne formatée par l'opérateur % :
- le motif %d permet d'afficher un nombre entier
- le motif %f permet d'afficher un nombre décimal
- le motif %s permet d'afficher une chaîne de caractères
A retenir :
Il existe 4 opérateurs applicables sur des chaînes de caractères en Python, les voici :
Les opérateurs applicables sur une chaîne de caractères |
|
opérateur |
opération effectuée |
+ |
concaténation de deux chaînes |
* |
multiplication d'une chaîne |
in |
test d'appartenance à une chaîne |
% |
formatage d'une chaîne de caractères contenant %d %f ou %s |
Voici les fonctions Python applicables à une chaîne de caractères :
Les fonctions externes applicables à une chaîne de caractères |
|
fonction |
opération effectuée |
len |
renvoie la longueur de la chaîne (nombre de caractères) |
sorted |
renvoie une liste avec les caractères rangés dans l'ordre croissant |
str |
convertit un objet en chaîne de caractères |
list |
convertit une chaîne de caractères en liste |
Il existe un grand nombre de méthodes applicables à un objet chaîne de caractères en Python. En voici quelques unes :
Les méthodes propres à une chaîne de caractères |
|
méthode |
opération effectuée |
upper |
convertit toute la chaîne en lettres majuscules |
capitalize |
met en majuscule la première lettre de la chaîne |
title |
met en majuscule la première lettre de chaque mot de la chaîne |
swapcase |
bascule la casse (minuscule/majuscule) de chaque caractère de la chaîne |
count |
compte le nombre de sous-chaîne présents dans la chaîne |
find |
renvoie la position d'une sous-chaîne (renvoie -1 si non trouvé) |
index |
renvoie la position d'un caractère (erreur si non trouvé) |
replace |
remplace une sous-chaîne par une autre |
split |
découpe la chaîne selon un séparateur (renvoie une liste) |
join |
utilise la chaîne comme séparateur pour joindre les éléments d'une liste (renvoie une chaîne) |
isxxxxx |
permet de tester si la chaîne est dans un format précis (numérique, alphabétique, etc.) |
Pour obtenir l'ensemble des méthodes applicables à une chaîne de caractères on pourra taper dir("chaine") dans une console Python : toutes les méthodes utilisables sont alors renvoyées dans une liste.
L'encodage des caractères en Python
En informatique les caractères sont enregistrés en mémoire sous forme d'un code numérique, appelé "code ASCII" pour les caractères les plus courant.
Les fonctions chr() et ord() permettent de passer d'un caractère à son code ASCII :
>>> ord('A')
65
>>> chr(65)
'A'
L'encodage consiste à remplacer un caractère (par exemple 'A') par son code numérique (par exemple 65) : c'est ce que fait la fonction ord()
Encodage : 'A' --> 65
Le décodage consiste à remplacer un code numérique (par exemple 65) par le caractère correspondant (par exemple 'A') : c'est ce que fait la fonction chr()
Décodage : 65 --> 'A'
Dans les 2 cas il faut utiliser un jeu de caractères précis, sachant qu'il en existe 3 sortes :
- la table ASCII de base (il n'y en a qu'une contenant 128 caractères)
- les tables ASCII étendues (il en existe plusieurs contenant chacune 256 caractères)
- l'Unicode (le jeu de caractère unique et définitif contenant plusieurs milliers de caractères)
La méthode encode() liée aux chaînes de caractères permet de retrouver l'encodage de la chaîne en utilisant un certain jeu de caractères :
>>> 'abc'.encode('ascii')
b'abc'
>>> 'é'.encode('latin_1')
b'\xe9'
>>> 'é'.encode('utf-8')
b'\xc3\xa9'
Pour Python 3 l'encodage par défaut est l'utf-8 :
>>> 'à'.encode()
b'\xc3\xa0'
>>> '€'.encode()
b'\xe2\x82\xac'
On obtient alors une chaîne "binaire" contenant la valeur des octets la constituant, et préfixée par b.
Un tel objet est de type bytes (et non str ou int) et sera appelé "une chaîne binaire" (par opposition à "une chaîne str") :
>>> b=b'\xe9'
>>> type(b)
<class 'bytes'>
Les objets de type bytes disposent d'une méthode decode() permettant de décoder la chaîne binaire, c'est-à-dire de passer de l'ensemble des valeurs numériques des octets aux caractères qui sont encodés. Là encore pour décoder une chaîne binaire (de type bytes) il faut préciser le jeu de caractères utilisé :
>>> a
b'\xe9'
>>> a.decode('iso8859')
'é'
>>> e=b'\xe2\x82\xac'
>>> e
b'\xe2\x82\xac'
>>> e.decode('utf-8')
'€'
En Python 3 la méthode de décodage utilisée par défaut est l'utf-8 :
>>> e=b'\xe2\x82\xac'
>>> e.decode()
'€'
>>> a=b'\xe9'
>>> a.decode()
Traceback (most recent call last):
File "<interactive input>", line 1, in <module>
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe9 in position 0: unexpected end of data
Remarque : le code \xe9 n'étant pas un code valide en UTF-8, Python renvoie alors une erreur : c'est un code en ISO8859 (ou latin) il faut alors le préciser à la méthode decode() sans quoi elle utilisera l'UTF-8.
Pour convertir un entier n (de type int) en chaîne binaire (de type bytes) il faut utiliser la méthode .to_bytes() liée aux entiers. Elle attend 2 paramètres :
- le nombre d'octets voulus
- l'ordre des octets (mettre 'big' pour commencer par le poids fort)
>>> n=181
>>> type(n)
<class 'int'>
>>> ch_b=n.to_bytes(1,'big')
>>> ch_b
b'\xb5'
>>> type(ch_b)
<class 'bytes'>
Pour convertir une chaîne binaire (de type bytes) en chaîne de caractère classique (de type str) il faut utiliser la méthode decode() liée aux chaînes binaires :
>>> ch_b
b'\xb5'
>>> type(ch_b)
<class 'bytes'>
>>> ch_s=ch_b.decode('cp1252')
>>> ch_s
'µ'
>>> type(ch_s)
<class 'str'>
Pour convertir une chaîne de caractères (de type str) en chaîne binaire (de type bytes) il faut utiliser la méthode encode() liée aux chaînes str :
>>> ch_s='é'
>>> type(ch_s)
<class 'str'>
>>> ch_b=ch_s.encode('cp1252')
>>> ch_b
b'\xe9'
>>> type(ch_b)
<class 'bytes'>
Par exemple pour afficher les caractères n°65 à n°74 de la table ASCII de base on tapera le programme suivant :
1 - n varie de 65 à 74
2 - on crée la chaîne binaire ch_b à partir de n
3 - on crée la chaîne de caractère ch_s à partir de ch_b et en utilisant le jeu de caractères 'ascii'
4 - on affiche le code n et la chaîne str ch_s
>>> for n in range(65,75):
... ch_b=n.to_bytes(1,'big')
... ch_s=ch_b.decode('ascii')
... print(n,' : ',ch_s)
...
65 : A
66 : B
67 : C
68 : D
69 : E
70 : F
71 : G
72 : H
73 : I
74 : J
Les différents jeux de caractères
1 - la table ASCII de base (128 caractères)
La table ASCII de base contient 128 caractères (de code 0 à 127) avec seulement 95 caractères imprimables (de code 32 à 126).
Voici la table ASCII complète (128 caractères dont les codes en décimal vont de 0 à 127) :
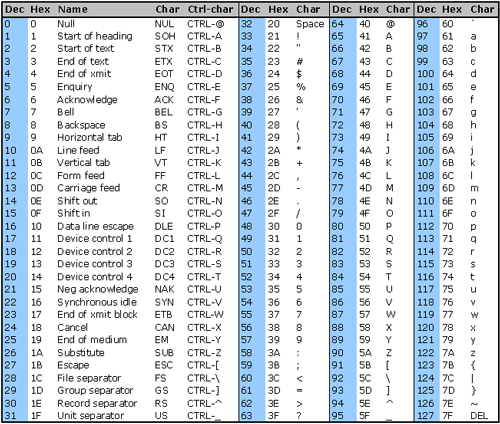
Table ASCII de base
Et voici seulement les 95 caractères imprimables de la table ASCII (code 32 à 126 en décimal) :
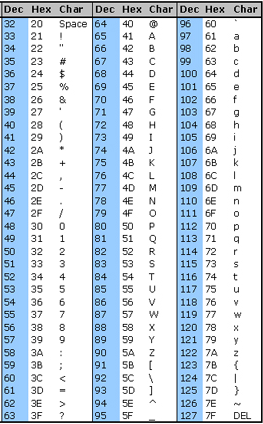
Table ASCII de base
Par exemple dans cette table ASCII on voit que le caractère 'A' correspond au code 65 en décimal.
Pour utiliser la table ASCII de base avec les méthode encode() et decode() de Python il faut indiquer le nom 'ascii' :
>>> 'A'.encode('ascii')
b'A'
>>> b'\x45'.decode('ascii')
'E'
On remarque que dans une chaîne binaire (de type bytes) si les caractères appartiennent à la table ASCII de base il sont affichés tels quels dans la chaîne binaire (comme pour une chaîne str).
En informatique les caractères spéciaux portent un nom précis, indépendant de la fonction qu'il peuvent remplir.
Voici le nom exact de 16 caractères spéciaux présents dans la table ASCII :
| caractère | nom |
|---|---|
# |
dièse |
& |
esperluette |
" |
double quote |
' |
simple quote |
* |
astérisque |
- |
trait d'union |
/ |
slash |
\ |
anti slash |
< |
chevron ouvrant |
> |
chevron fermant |
^ |
accent circonflexe |
` |
accent grave |
| |
barre verticale |
_ |
underscore |
@ |
arobase |
~ |
tilde |
2 - les tables ASCII étendues (256 caractères)
En principe le terme "table ASCII" devrait être réservé à la table ASCII de base possédant seulement 128 caractères (il n'y en a qu'une).
Les tables ASCII étendues à 256 caractères devraient être appelées des pages de code (il y en a plusieurs, selon le pays dans lequel elles sont utilisées).
La table ASCII étendue ANSI porte différents noms :
- latin
- cp1252
- iso8859
- iso8859-15
>>> 'à'.encode('latin')
b'\xe0'
>>> 'à'.encode('cp1252')
b'\xe0'
>>> 'à'.encode('iso8859')
b'\xe0'
>>> 'à'.encode('iso8859-15')
b'\xe0'
La table ASCII étendue utilisée par le système d'exploitation Microsoft Windows est la page de code Windows-1252 (noté cp1252 dans Python, cp signifiant "Code Page", soit "page de code") et appelée "table ANSI".
Les autres tables ASCII étendues :
La table ASCII OEM correspond à la page de code n°437 (noté cp437 pour Python). Elle est utilisée par les systèmes IBM et Microsoft en Amérique :
>>> 'à'.encode('cp437')
b'\x85'
La table ASCII étendue utilisée par le système d'exploitation MS-DOS de Microsoft en Europe occidentale est la page de code n°850 (noté cp850 dans Python) :
>>> 'à'.encode('cp850')
b'\x85'
La table ASCII étendue utilisée par les systèmes d'exploitation Apple est la page de code MAC Roman (noté mac-roman dans Python)
>>> 'à'.encode('mac-roman')
b'\x88'
Pour afficher les tables ASCII étendue OEM et ANSI dans un document PDF cliquez ici.
Pour afficher la table ASCII ANSI (page de code cp1252) dans une nouvelle page web cliquez ici.
3 - l'unicode
L'unicode est le jeu de caractères universel, utilisé par tous et désormais pour toujours. Il contient plusieurs milliers de caractères, possédant chacun un numéro unique appelé "point de code".
Pour utiliser le jeu de caractères Unicode et obtenir le point de code d'un caractère il faut préciser 'unicode_escape' en paramètre de la méthode encode() :
>>> "€".encode('unicode_escape')
b'\\u20ac'
Remarque : la fonction ord() de Python donne également le point de code d'un caractère unicode, mais en décimal. Si on veut le point de code en hexadécimal il faudra le convertir grâce à la fonction hex() :
>>> ord('€')
8364
>>> hex(ord('€'))
'0x20ac'
On en déduit que :
- '€'.encode('unicode_escape') renvoie une chaîne binaire (de type bytes)
- hex(ord('€')) renvoie une chaîne classsique (de type str)
- dans tous les cas le point de code du caractère '€' est 20AC(16)
Et comme la fonction chr() de Python permet d'afficher un caractère à partir de son code numérique en décimal, il est possible d'obtenir le caractère Euro connaissant son point de code en décimal (appel direct de chr()) ou en hexadécimal (conversion grâce à int()) :
>>> chr(8364)
'€'
>>> chr(int('20ac',16))
'€'
Pour savoir comment un caractère unicode est codé en UTF-8, il faut préciser l'algorithme d'encodage qui s'appelle UTF-8 (noté utf-8 dans Python) :
>>> 'à'.encode('utf-8')
b'\xc3\xa0'
UTF-8 est l'abréviation de l'anglais Universal character set Transformation Format - 8 bits.
Les caractères unicode sont codés sur 1, 2, 3 ou 4 octets grâce à UTF-8 : les caractères les plus courant sont codés sur 1 octet (comme pour la table ASCII de base), et les caractères plus rares sont codés sur 2 à 4 octets. Par exemple on peut remarquer que le caractère 'à' est codé sur 2 octets en UTF-8.
Remarque : si on ne précise pas le jeu de caractères pour l'encodage, Python 3 utilisera toujours UTF-8 comme encodage par défaut :
>>> 'à'.encode()
b'\xc3\xa0'
Enfin, pour décoder une séquence d'octets codée en UTF-8, il faut utiliser la méthode decode() liée aux chaînes binaires :
>>> ch_b=b'\xc3\xa0'
>>> ch_b.decode('utf-8')
'à'
>>> ch_b.decode()
'à'
>>> ch_b='€'.encode('utf-8')
>>> ch_b
b'\xe2\x82\xac'
>>> ch_b.decode('utf-8')
'€'
>>> ch_b.decode()
'€'
Remarque : si on ne précise pas l'algorithme de décodage à la méthode decode(), Python 3 utilisera toujours UTF-8 comme décodage par défaut.
Écriture d'une chaîne de caractères
Pour écrire une chaîne de caractère (de type str) il suffit de taper les caractères entre des simples quotes :
>>> ch='bonjour'
>>> type(ch)
<class 'str'>
C'est facile si les caractères son imprimés sur le clavier (exemple : les lettres de l'alphabet latin, mais ce ne sont que 26 caractères sur plus de 100 000 existants ...), mais c'est plus délicat pour les milliers de caractères du répertoire unicode qui ne sont pas sur le clavier. Exemple : comment utiliser le caractère 'fleur' alors qu'aucune fleur n'est dessinée sur les touches du clavier ? ?
On peut justement aussi préciser dans la chaîne non pas les caractères directement, mais leur code numérique. Comme en Python 3 les chaînes sont en unicode, il s'agit alors des points de code dans la table unicode.
Exemple : pour écrire un A dans une chaîne on peut saisir \x41 pour le caractère A a pour code ASCII 0x41 :
>>> ch='\x41'
>>> ch
'A'
Autre exemple : pour écrire le caractère copyright (de code 0xA9) au milieu d'une chaîne il faut insérer la séquence \xa9 dans la chaîne :
>>> ch='Voici le caractère copyright : \xa9'
>>> print(ch)
Voici le caractère copyright : ©
Pour écrire un caractère unicode dont le point de code est sur 2 octets il faut insérer la séquence \uxxxx où xxxx est le point de code sur 4 chiffres en hexadécimal. Exemple :
>>> ch='Voici un crayon : \u270f'
>>> ch='Et voici notre petite fleur ! \u2740'
Enfin, si on veut préciser le point de code d'un caractère unicode sur 4 octets il faut utiliser la séquence \Uxxxxxxxx (avec un U MAJUSCULE) :
>>> '\x41'
'A'
>>> '\u0041'
'A'
>>> '\U00000041'
'A'
A retenir :
Pour insérer un caractère unicode dans une chaîne de caractère en précisant son point de code en hexadécimal il faut le préfixer par :
- \x si le point de code est sur 1 octet
- \u si le point de code est sur 2 octets
- \U si le point de code est sur 4 octets
Unicode et UTF-8
Unicode :
Unicode est un jeu de caractères universel et définitif : il contient tous les alphabets connus à ce jour et contient en plus des milliers de nouveaux symboles ou pictogrammes.
Il contient plus de 100 000 caractères en tout aujourd'hui et évolue constamment. Dans la table unicode chaque caractère possède un code numérique unique appelé point de code
Le point de code est un nombre entre 7 et 21 bits (2 millions de possibilités) et se note U+xxxx avec xxxx sa valeur en hexadécimal.
Exemple : U+2740 seprésente "le caractère unicode qui a pour point de code 2740 en hexadécimal".
UTF-8 :
UTF-8 est l’algorithme permettant d’encoder un caractère de la table unicode en une séquence d'octets contenant 1 à 4 octets.
UTF-8 permet de convertir un point de code (valeur entre 0 et 2 000 000) en une suite d’octets contenant 1 à 4 octets.
Le décodage d'UTF-8 consiste à revenir au point de code à partir de la suite d’octets.
Le nombre d'octets codant le caractère dans la séquence UTF-8 dépend du point de code :
- Si le point de code s’écrit sur 7 bits (de 0 à 127) alors le caractère se code sur 1 octet en UTF-8
- Si le point de code s’écrit sur 8 à 11 bits (de 128 à 2047) alors le caractère se code sur 2 octets en UTF-8
- Si le point de code s’écrit sur 12 à 16 bits (de 2048 à 65535) alors le caractère se code sur 3 octets en UTF-8
- Si le point de code s’écrit sur 17 à 21 bits (plus de 65535) alors le caractère se code sur 4 octets en UTF-8
Remarque importante concernant l'écriture des nombres pour la suite :
- les nombres hexadécimaux sont préfixés par 0x. Exemple : 0x41 signifie "le nombre 41 exprimé en hexadécimal", soit 41(16)
- les nombres en binaire naturel sont préfixés par 0b. Exemple : 0b11101001 signifie "le nombre 11101001 exprimé en binaire naturel", soit 11101001(2)
Encodage UTF-8 sur 1 octet :
- Les points de code 0 à 127 se codent sur 7 bits
- L’octet est alors de la forme 0xxxxxxx
- Le bits de poids fort est toujours à 0
- Les 7 bits xxxxxxx représentent le point de code
- Il s’agit des 128 caractères de la table ASCII de base
- Exemple : comment se code le caractère ‘A’ en UTF-8 ? Point de code = 0x41 donc il se code sur 1 octet car il est inférieur à 128 : 001000001
- Illustration avec Python :
>>> 'A'.encode()
b'A'
>>> hex(ord('A'))
'0x41'
>>> '\x41'.encode()
b'A'
Encodage UTF-8 sur 2 octets
- Ce sont les points de code nécessitant 8 à 11 bits
- Soit les valeurs 128 à 2047
- Les 11 bits sont répartis sur 2 octets ayant le format suivant : 110xxxxx 10xxxxxx
- Les 2 bits de poids fort du 1er octet sont à 1
- Exemple : comment se code le caractère ‘é’ en UTF-8 sachant que son point de code est 233 = 0xE9 ?
- Réponse : 0xE9 = 0b11101001 sur 8 bits, soit 0b00011101001 sur 11 bits
- donc le caractère ‘é’ se code sur 2 octets en UTF-8 : 11000011 10101001 soit \xC3 \xA9 en hexadécimal sur 2 octets
- les bits en rouge ci-dessus sont les bits à valeur constante dans l'encodage UTF-8 sur 2 octets
- les bits en bleu ci-dessus sont les 11 bits du point de code (ici 0xE9 soit 0b00011101001)
- Illustration avec Python dans 2 cas différents :
>>> 'é'.encode()
b'\xc3\xa9'
>>> hex(ord('é'))
'0xe9'
>>> '\xe9'.encode()
b'\xc3\xa9'
Remarque : le point de code du caratère é est sur 1 octet (\xe9) et son encodage en UTF-8 est bien sur 2 octets (\xc3\xa9)
>>> 'Ω'.encode()
b'\xce\xa9'
>>> hex(ord('Ω'))
'0x3a9'
>>> '\u03a9'.encode()
b'\xce\xa9'
>>> ord('Ω')
937
Remarque : le point de code du caratère Ω est sur 2 octets (\u03a9) et son encodage en UTF-8 est également sur 2 octets (\xce\xa9)
Comme le (point de) code en décimal du caractère Ω est 937 dans le jeu de caractères Unicode il s'obtient par la séquence de touche Alt-937
Encodage UTF-8 sur 3 octets
- Ce sont les points de code nécessitant 12 à 16 bits
- Soit les valeurs 2048 à 65 535
- Les 16 bits sont répartis sur 3 octets ayant le format suivant : 1110xxxx 10xxxxxx 10xxxxxx
- Les 3 bits de poids fort du 1er octet sont à 1
- Exemple : comment se code le caractère ‘€’ en UTF-8 sachant que son point de code est 8364 = 0x20AC ?
- Réponse : 0x20AC = 0b10000010101100 = 14 bits donc 3 octets : 11100010 10000010 10101100 soit \xE2 \x82 \xAC en hexadécimal sur 3 octets
- Illustration avec Python :
>>> '€'.encode()
b'\xe2\x82\xac'
>>> hex(ord('€'))
'0x20ac'
>>> '\u20ac'.encode()
b'\xe2\x82\xac'
Encodage UTF-8 sur 4 octets
- Ce sont les points de code nécessitant 17 à 21 bits
- Soit les valeurs supérieures à 65 535
- Les 21 bits sont répartis sur 4 octets ayant le format suivant : 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
- Les 4 bits de poids fort du 1er octet sont à 1
- Exemple : comment se code le caractère ‘ île’ en UTF-8 sachant que son point de code est 127796= 0x1F334 ?
- Réponse : 0x1F334 = 0b11111001100110100 = 17 bits donc 4 octets : 11110000 10011111 10001100 10110100 soit \xF0 \x9F \x8C \xB4 en hexadécimal sur 4 octets
- Illustration avec Python :
>>> '\U0001f334'.encode()
b'\xf0\x9f\x8c\xb4'
A retenir :
UTF-8 permet de convertir un point de code unicode en une séquence de 1 à 4 octets selon l'algorithme suivant :
Conversion d'un point de code en séquence d'octets par UTF-8 |
||||
Intervalle du |
Taille du |
Format de l'UTF-8 |
Encodage UTF-8 |
|
en décimal |
en hexadécimal |
|||
de 0 à 127 |
de 0x00 à 0x7F |
7 bits |
1 octet |
0xxxxxxx |
de 128 à 2047 |
de 0x80 à 0x7FF |
8 à 11 bits |
2 octets |
110xxxxx 10xxxxxx |
de 2048 à 65535 |
de 0x800 à 0xFFFF |
12 à 16 bits |
3 octets |
1110xxxx 10xxxxxx 10xxxxxx |
65536 et plus |
0x10000 et plus |
17 à 21 bits |
4 octets |
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
Si UTF-8 n'existait pas, chaque caractère unicode devrait être codé sur 4 octets, et les simples fichiers texte prendraient alors 4 fois plus de place qu'avec un codage ASCII classique.
Grâce à UTF-8 :
- les caractères les plus utilisés sont codé sur 1 octet
- les caractères un peu moins utilisés sont codés sur 2 octets
- les caractères rares sont codés sur 3 octets
- et seulement les caractères très rares sont codés sur 4 octets
De plus, UTF-8 reste compatible avec ASCII : les 128 caractères de la table ASCII de base se codent de la même manière en UTF-8 et en ASCII (1 octet par caractère compris entre 0 et 127).
Pour aller plus loin : le module encodings
Le module encodings permet d'encoder une chaîne de caractères en utilisant un certain jeu de caractères :
import encodings
La fonction encodings.aliases.aliases.values() donne l'ensemble des jeux de caractères utilisables (sous forme de dictionnaire). Pour obtenir une liste triée, claire et sans doublon on pourra taper par exemple la commande suivante dans la console Python :
>>> sorted(set(encodings.aliases.aliases.values()))
['ascii',
'big5',
'big5hkscs',
'cp037',
'cp1026',
'cp1140',
'cp1250',
'cp1251',
'cp1252',
'cp1253',
'cp1254',
'cp1255',
'cp1256',
'cp1257',
'cp1258',
'cp424',
'cp437',
'cp500',
'cp775',
'cp850',
'cp852',
'cp855',
'cp857',
'cp858',
'cp860',
'cp861',
'cp862',
'cp863',
'cp864',
'cp865',
'cp866',
'cp869',
'cp932',
'cp949',
'cp950',
'euc_jis_2004',
'euc_jisx0213',
'euc_jp',
'euc_kr',
'gb18030',
'gb2312',
'gbk',
'hp_roman8',
'hz',
'iso2022_jp',
'iso2022_jp_1',
'iso2022_jp_2',
'iso2022_jp_2004',
'iso2022_jp_3',
'iso2022_jp_ext',
'iso2022_kr',
'iso8859_10',
'iso8859_11',
'iso8859_13',
'iso8859_14',
'iso8859_15',
'iso8859_16',
'iso8859_2',
'iso8859_3',
'iso8859_4',
'iso8859_5',
'iso8859_6',
'iso8859_7',
'iso8859_8',
'iso8859_9',
'johab',
'koi8_r',
'latin_1',
'mac_cyrillic',
'mac_greek',
'mac_iceland',
'mac_latin2',
'mac_roman',
'mac_turkish',
'mbcs',
'ptcp154',
'shift_jis',
'shift_jis_2004',
'shift_jisx0213',
'tactis',
'tis_620',
'utf_16',
'utf_16_be',
'utf_16_le',
'utf_32',
'utf_32_be',
'utf_32_le',
'utf_7',
'utf_8']
Le module codecs propose les fonctions encode() et decode() permettant d'encoder ou de décoder une chaîne de caractères :
>>> import codecs
>>> codecs.encode('é')
b'\xc3\xa9'
>>> codecs.encode('é','latin_1')
b'\xe9'
>>> codecs.decode(b'\xc3\xa9')
'é'
>>> codecs.decode(b'\xe9','latin_1')
'é'
Rappel : en Python 3 l'encodage par défaut est l'UTF-8.
La fonction unicode_escape_encode() du module codecs permet de passer directement d'un caractère à son point de code unicode.
Exemple : quel est le point de code du caractère Euro ?
>>> codecs.unicode_escape_encode('€')
(b'\\u20ac', 1)
Réponse obtenue grâce à la fonction codecs.unicode_escape_encode() : le point de code du caractère € est U+20AC